4 Intelligent Agents New Technology To The Rescue
We have identified the main problems that need to be addressed to be
able to come up with an efficient way of searching as much of the Web as
easily as possible. Having taken a look at what requirements we have for
a new Web search technology, we proceed to let this chapter provide us
with an introduction to relevant aspects of the concept intelligent agents,
a relatively new technology.
4.1 Intelligent Agents
Until it was discovered that some of the large apes use straws to fish
termites for eating, the fact that human beings develop tools to get things
done, was considered one of the major differences between the animals and
us. Although we cannot claim to be the only ones using tools anymore, it
must be admitted that we are pretty good at inventing tools for performing
tasks we could not possibly do manually. One of the latest tools the computer
industry has come up with is the intelligent agent technology.
Like many brand new technologies that have not been clearly defined
from the start, agent, originally a theoretical concept borrowed from
the Artificial Intelligence community, has become an over-used term. Pattie
Maes [Maes, 1997] is a central
person in the international agent research community, and presents agents
as a computational system which:
- is long-lived, meaning it has a kind of life cycle to go through;
- has goals, sensors and effectors, meaning it has a clearly defined
purpose and the means to sense and act in its surroundings;
- decides autonomously which actions to take in any current situation
to maximize progress towards its (time-varying) goals.
In other words, according to this definition an agent is software that
lets the user define what is eventually or instantly wanted, and works
towards that goal, without the user having to worry about anything else
than waiting for the results from the agent's work.
[Nwana, 1996] is more reluctant
towards defining agents, but uses the word carefully and selectively in
various settings. When we really have to, we define an agent as referring
to a component of software and/or hardware which is capable of acting exactingly
in order to accomplish tasks on behalf of its user.
Rather than being a definable term, Nwana says, agents should be considered
an umbrella term, meta-term or class, covering a range of specific agent
types that have been developed. Some agents automate and personalize user
interface operations, other agents function as guardians patrolling computer
networks and fixing errors and reporting errors they can not fix themselves.
The computer game industry uses agents to create opponents or partners
for game players, and there are also agents that act as assistants to experts
in various fields.
4.2 Intelligence
The intelligent part of intelligent agents is not so much emphasized
anymore. Although it may seem as if the software acts intelligently, it
is actually just a matter of applying certain rules to the situation in
a suitable manner. These rules, the agents brains, are the components
of the agents knowledge database. The agent can acquire its rules, that
is learn, in several ways. Let us take a look at how it can be done by
what [Maes, 1997] calls a software
agent and what [Nwana, 1996]
calls an interface agent.
A software/interface agent is an agent that assists its owner, a user,
in the use of a specific application or user interface. The interface agent
may observe many user actions, over a long period of time, before deciding
to take a single action, or a single user input may launch a series of
actions on the part of the agent, also possibly over a long period of time.
As shown in the figure below, the agent can learn through a variety of
processes:
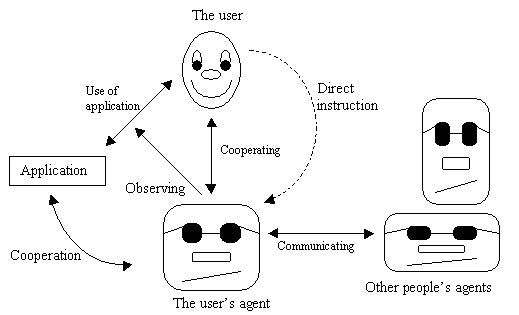 Figure 4-1, Agent learning
Figure 4-1, Agent learning
-
Observing the users activity using the application, e.g. identifying patterns
of behavior that can be automated and/or used to create a profile for the
user
-
Cooperating with the application, e.g. predict data necessary for future
operations and retrieve them for a potentially quicker access for the application
-
Cooperating with the user, asking the user for instructions when in doubt
about whether to act or not.
-
Being directly instructed by the user, e.g. the user defining new goals
for the agent
-
Communicating with other agents, e.g. learning where to look for information
regarding specific topics, based on their experience
The apparent intelligence shown by the agent is a result of acting in accordance
with the rules in the agents knowledge base. These rules may come from:
-
Standard background knowledge that the agent is supplied with by the agent
manufacturer.
-
Personal knowledge that the user can somehow program the agent to know.
This is useful both when the agent is new and not yet familiar with its
owner, and later when the users preferences and behavior changes more
or less drastically.
-
The agent can automatically learn rules from observing, and build confidence
in using the rules through suggesting actions for the user and have the
user accept, decline or comment on them.
4.3 Why Agents Are Used
The main motivation for the introduction of agents is that we are heading
for a future where the following will apply:
-
An increasing number of our everyday tasks will become computer-based
-
Vast amounts of unstructured, dynamic information will be unleashed
-
More and more users will be introduced to computers and the Internet in
their work, and many of them so without being thoroughly trained for it.
Hence, it is necessary to come up with something that will make computer
and Net operations easier to perform. Software agents seem to be a good
solution, although there is still much to be done to make them perform
better. Agents must know how their actions can change the world, and
they must also know as much as possible about their owners interests,
habits and preferences. With this in mind, the agents can make suggestions
and/or act on behalf of their owner. They also can operate even when the
human user is not logged on, and they can typically do things faster than
their owner can when fast actions are called for. The knowledge necessary
for all this is a combination of standard knowledge that many agents have
in common and the user-specific information the agent acquires through
the channels described above (observation, direct instruction and cooperation/communication).
In the end, it all comes down to defining rules for the agents activities,
and define goals that can be reached by acting according to these rules.
4.4 An Agent Example: E-mail Information Agent
Among the first applications to introduce agents were the e-mail applications.
This environment provides a suitable example on various thinkable kinds
of agent functionality. Let us imagine a busy businessperson who receives
literally hundreds of e-mails every day, a mixture of personal e-mails
and mails from a number of e-mail lists she subscribes to. She moves around
a lot to attend meetings and conferences, and she depends on always having
access to the latest information. Her most important tool for ensuring
up-to-date information is her personal e-mail information agent, who may
have the following functionality:
Simple agent functionality:
-
After having observed how she reads her e-mail, the agent develops an impression
of which e-mails she reads instantly, which e-mails she reads eventually
and which e-mails she does not bother to look at at all. Based on who the
sender of an e-mail is and what the subject line says, the agent can use
its knowledge to sort the incoming, unread e-mail for its owner, so that
the most important e-mails are most likely to appear on top of the list
of incoming e-mails. The owner can also directly instruct the agent by
maintaining a list of e-mail addresses that is always to be considered
important senders, for instance.
-
The agent can browse through the contents of the e-mails as soon as they
arrive, and see if there are any references in the shape of URLs to be
found. If the agent finds such references, it can tell the Web browser
(or the agent responsible for handling Web references) to retrieve the
references to the computers local Web cache, so that the owner can quickly
look up the information if she wants to.
-
If the person sees that another person has an agent that seems to act exactly
like she wants her own agent to do, she can ask this person for permission
to copy the rules used by the other persons agent. This is based on the
idea that if other users are like me, my agent should act like their agents
per default. Since the agents work using a number of rules, all of or
parts of these rules can be exported to and used by other agents. Typically,
people would be interested in being able to import an efficient set of
rules for very specific subjects, such as Retrieve high quality information
about publications concerning intelligent agents.
Advanced agent functionality:
-
The e-mail agent can act as a secretary. If the people the businessperson
is to meet also use e-mail agents, the agents can communicate between themselves,
e.g. compare their owners schedules, which may be available from special
scheduling agents, and find the best times for meetings. Having found a
suitable date and time for a meeting by sending a number of e-mails between
each other, they communicate this to the scheduling agents that update
the schedules with the new meeting information.
-
If the agent gathers from an incoming e-mail that it is a very urgent/important
e-mail, and the agent also knows that at this moment, according to her
schedule/ scheduling agent, its owner is travelling between her office
and a meeting somewhere, it can generate a message for her cellular phone/beeper,
telling her to check her e-mail immediately.
-
When the agent is in doubt about what to do at some stage, it can take
its problem to other, more experienced agents, show them the information
it has and ask them for advice. For example, the user may seem to always
immediately delete so-called spam mail, meaning e-mail advertisements.
The agent ideally takes care of this, but in some cases it may be difficult
to decide whether an e-mail is spam or not. In these cases it may perform
a content analysis of the e-mail, and if necessary even go to other e-mail
agents and ask them whether they believe this is spam. If e.g. more than
six out of ten agents can report that Yes, I received that e-mail as well,
and I considered it to be spam, our agent can assume that it really is
spam, and go ahead and delete it.
-
By reading and analyzing all the e-mails and sorting them according to
keywords either chosen by the owner or picked by the agent, the agent stores
all read e-mails in an indexed mail hierarchy. By doing this, the owner
can tell the agent to perform actions like I want you to list all the
e-mails I got about the new economy project in September, Please list
all mails containing invitations to conferences and seminars taking place
in Hawaii this winter, and so on. This provides a very flexible but also
efficient way of looking through old e-mails.
4.5 How Agents Travel and Talk
Most people are confused by the concept of agents moving around on the
Net doing their job. However, it is important to keep in mind that agent
itself is only a concept, which in reality is just a piece of software
being run somewhere. It can be difficult to come up with an answer to the
question What can you do with mobile agents that you cannot do with stationary
agents?, so we will not concentrate on the possibility of using mobile
agents in this paper. However, there are several reasons in general for
running software remotely instead of locally:
-
To reduce network traffic
-
To share computer load among several computers
-
To move the program to the data if the data can not come to the program
-
To enable the user to get things done even while disconnected from the
network
There is an increasing number of options, most of them developed fairly
recently, when it comes to script and programming languages that allow
running programs remotely, thus providing agents with mobility and the
ability to communicate with agents both locally and on other locations:
-
Tcl/Tk: Executing scripts remotely.
-
Telescript: A script language especially designed for agent operations.
Using Telescript, agents go to centralized servers, conduct their business,
return to their users distributed locations with the results and present
them to the users.
-
Java: Java-programs, applets, can move on the Internet through distributed,
Java-enabled Web browsers, bringing both data and program with them and
execute locally.
In the future, the mobility of agents will probably not be so much focused
on. The most likely scenario is that agents will stay at home and conduct
their work through communication with other agents elsewhere. A standard
language for communication in agent communities has not been chosen yet,
but this will probably happen soon, simply because it has to.
There are two popular approaches to the design of a communication language
[Genesereth, 1994]. The procedural approach is
based on the idea that communication can best be modeled as the exchange
of procedural directives. Script languages like the already mentioned Tcl/Tk
and Telescript are based on this approach, and offer simple but powerful
possibilities. However, there are disadvantages to a purely procedural
approach. The flexibility required for bi-directional communication and
general non-directed requests is especially difficult to produce with script
languages.
The other approach is the declarative one. This is based on the idea
that communication is best modeled as the exchange of declarative statements.
A declarative language must be sufficiently expressive to communicate a
wide range of information, including procedures. The ARPA Knowledge Sharing
Effort has outlined the components of an agent communication language (ACL)
that belongs to the declarative approach.
ACL consists of three parts:
-
A vocabulary where all words have an English description for use by humans
in understanding the meaning of the word, and formal annotations for use
by programs/agents. In this way an ontology is created, where many different
human words can all map to the same formal concept.
-
Knowledge Interchange Format (KIF), an inner language which is a prefix
version of first order predicate calculus, with extensions to enhance expressiveness.
-
Knowledge Query and Manipulation Language (KQML), an outer language which
can be used to form expressions suitable for communication.
To sum it up, an ACL message is a KQML expression in which the arguments
are terms or sentences in KIF formed from words in the ACL vocabulary.
These messages need to be understood by a variety of agents and agent types,
since although many agents provide their owners with valuable functionality,
many problems that need to be solved can not be solved by one agent alone.
4.6 A Look in the Rearview Mirror: Letizia
When people can not find and do not know where to look for the information
they need, they sometimes try to find it by moving from page to page, following
links that seem to be likely to lead to something they may be interested
in. This is what is called a depth-first search or exploration, and is
based on the idea that often a hyperlink leads to a different page which
is in the same context as the page the link goes from. This is what is
called depth-first search or exploration. However, the technique may take
the user to pages containing all kinds of information not necessarily of
the kind the user is looking for, and often leads to the user feeling lost
in hyperspace. So far, no major Web browsers offer navigation possibilities
that actively prevent this from happening.
Henry [Lieberman, 1997] has introduced Letizia
to do something about the problem. Letizia is an agent that aids the user
in searching the Web, through assisting the user in the Web browsing process.
This autonomous information/interface agent tracks user behavior and attempts
to anticipate items of interest by doing a concurrent, autonomous exploration
of links from the users current position. In other words, it performs
a breadth-first exploration of the Web. Letizia can explore search alternatives
faster than the user can, and the agent can explore the Web while the user
is working, reading or exploring on his own, taking advantage of computer
resources that are available anyway. Letizia is one of the first attempts
on using agent technology to aid people in searching the Web.
The Letizia interface is shown in Figure 4-2. The user is browsing as
usual in the largest window, to the left. The agent controls the two windows
on the right, and the user can choose to ignore these windows completely.
The top right window displays search candidates, meaning the pages Letizia
is considering for recommendation to the user. The bottom right window
displays the pages that actually are recommended to the user for further
exploration.
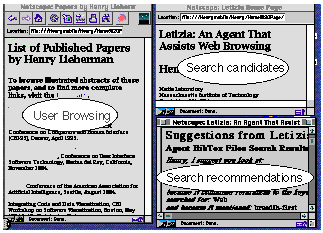 Figure 4-2, Screenshot from the Letizia agent used with Netscape
Figure 4-2, Screenshot from the Letizia agent used with Netscape
The work Letizia does is a blend of information retrieval and information
filtering. The user saves retrieval time, by having the agent retrieve
potentially interesting pages while the user reads the current page. Letizia
also performs an analysis of what pages the user is most likely to want
to read next, and presents the pages to the user in a ranked order. This
analysis is based partially on documents the user has read previously,
but mainly on the document the user is reading at the moment. Letizia is
never in control of the browser, it is for the user to decide whether to
use the agents suggestions or not. The best use of Letizias recommendations
is when the user is unsure of what to look at next.
Letizia does not have a natural language understanding capability, so
its content model of a document is simply a list of keywords, deducted
from the contents of the Web pages the user seems to show an interest in.
The agent remembers and looks out for the interests/keywords that the user
expresses through his actions while browsing. Interests that are not repeatedly
observed decays over time, so that the agent is not clogged with searching
interests that may have fallen from the users attention.
The technique used to compute the content of a document is a simple
keyword frequency measure, tf*idf (term frequency times inverse document
frequency). This is based on the idea that keywords that are relatively
common in the document, but relatively rare in general, are good indicators
of the content. We will take a closer look at this technique in the following.
It is not 100% accurate, but it has been sufficient for the purpose of
Letizia.
Go to: Front
page - Index - Ch.
1 - Ch. 2 - Ch.
3 - Ch. 4 - Ch.
5 - Ch. 6 - Ch.
7 - Ch. 8 - Ch.
9 - Glossary - References
Visit the author's homepage : http://www.pvv.org/~bct/
E-mail the author, Bjørn Christian Tørrissen:
bct@pvv.org