|
|||
| Forrige < |
Innhold ^
|
Neste >
|
|
SongList klasse, som kan spesialiseres for kataloger og avspillingslister.
SongList objektet. Vi har tre åpenbare valg. Vi kan bruke Ruby sin tabelltype (Array), bruke Ruby sin hashtabelltype (Hash) eller lage vår egen listestruktur.
Late som vi er, holder vi oss foreløpig til Array og Hash, og velger en av disse som utgangspunkt.
Array holder styr på en samling av objektreferanser.
Hver referanse tar opp en posisjon i tabellen, identifisert med en heltallsindeks som ikke kan være negativ.
Du kan lage litterale tabeller direkte i koden eller eksplisitt lage et Array-objekt. En tabell litteral er intet mer enn en list av objekter mellom to hakeparenteser.
a = [ 3.14159, "pie", 99 ]
|
||
a.type
|
» |
Array
|
a.length
|
» |
3
|
a[0]
|
» |
3.14159
|
a[1]
|
» |
"pie"
|
a[2]
|
» |
99
|
a[3]
|
» |
nil
|
|
||
b = Array.new
|
||
b.type
|
» |
Array
|
b.length
|
» |
0
|
b[0] = "second"
|
||
b[1] = "array"
|
||
b
|
» |
["second", "array"]
|
[]-operatoren. Som med de fleste operatorene i Ruby, er dette egentlig en metode (i Array klassen) og kan dermed redefineres i subklasser.
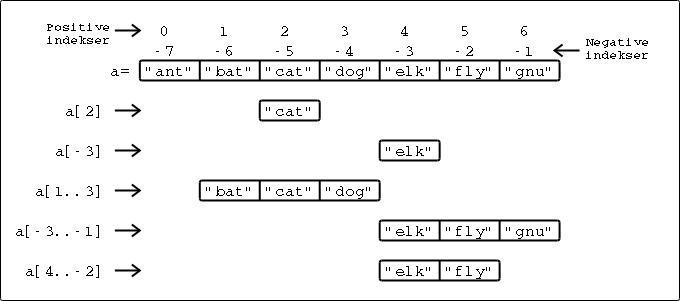
Vi ser i eksempelet at indekseringen starter på null. Dersom du slår opp i en tabell med bare et heltall, returneres objektet som er på den posisjonen eller
nil hvis det ikke var noe der. Negative heltall gjør at oppslaget teller bakover i fra slutten. Dette vises i figur 4.1 som følger.
| Figur 4.1: Indeksering av tabeller |
|
a = [ 1, 3, 5, 7, 9 ]
|
||
a[-1]
|
» |
9
|
a[-2]
|
» |
7
|
a[-99]
|
» |
nil
|
[start, antall]. Dette returnerer en ny tabell som består av referansene til de antall objektene som var i den oppprinnelige tabellen fra posisjon start og utover.
a = [ 1, 3, 5, 7, 9 ]
|
||
a[1, 3]
|
» |
[3, 5, 7]
|
a[3, 1]
|
» |
[7]
|
a[-3, 2]
|
» |
[5, 7]
|
a = [ 1, 3, 5, 7, 9 ]
|
||
a[1..3]
|
» |
[3, 5, 7]
|
a[1...3]
|
» |
[3, 5]
|
a[3..3]
|
» |
[7]
|
a[-3..-1]
|
» |
[5, 7, 9]
|
[] har en tilsvarende []= operator som kan brukes for å sette elementer i tabellen. Brukes den med et enkelt heltall, blir elementet på den posisjonen byttet ut med hva enn som er på høyresiden av tilordningen. Eventuelle tomrom fylles med nil.
| a = [ 1, 3, 5, 7, 9 ] | » | [1, 3, 5, 7, 9] |
| a[1] = 'bat' | » | [1, "bat", 5, 7, 9] |
| a[-3] = 'cat' | » | [1, "bat", "cat", 7, 9] |
| a[3] = [ 9, 8 ] | » | [1, "bat", "cat", [9, 8], 9] |
| a[6] = 99 | » | [1, "bat", "cat", [9, 8], 9, nil, 99] |
[]= mottar to tall (en startindeks og en lengde) eller en rekkevidde, da blir de angitte elementene i den opprinnelige tabellen byttet ut med det som er på høyresiden av tilordningen. Dersom lengden er null vil uttrykket på høyre side smettes inn før startposisjonen og ingen elementer blir fjernet. Hvis uttrykket på høyresiden også er en tabell, blir elementene den inneholder brukt i overskrivningen.
Størrelsen på tabellen justeres automatisk dersom indeksen velger et annet antall elementer enn det som er tilgjengelig på høyresiden.
| a = [ 1, 3, 5, 7, 9 ] | » | [1, 3, 5, 7, 9] |
| a[2, 2] = 'cat' | » | [1, 3, "cat", 9] |
| a[2, 0] = 'dog' | » | [1, 3, "dog", "cat", 9] |
| a[1, 1] = [ 9, 8, 7 ] | » | [1, 9, 8, 7, "dog", "cat", 9] |
| a[0..3] = [] | » | ["dog", "cat", 9] |
| a[5] = 99 | » | ["dog", "cat", 9, nil, nil, 99] |
=> verdi par mellom klammeparenteser.
h = { 'dog' => 'canine', 'cat' => 'feline', 'donkey' => 'asinine' }
|
||
|
||
h.length
|
» |
3
|
h['dog']
|
» |
"canine"
|
h['cow'] = 'bovine'
|
||
h[12] = 'dodecine'
|
||
h['cat'] = 99
|
||
h
|
» |
{"donkey"=>"asinine", "cow"=>"bovine", "dog"=>"canine", 12=>"dodecine", "cat"=>99}
|
Hash-klassen begynner på side 317(??).
SongList. La oss finne ut hvilke grunnleggende metoder vi trenger i vår SongList. Underveis vil flere metoder komme til, men foreløpig vil dette holde.
Array. Videre er også muligheten for å hente ut en sang utifra en heltallsindeks også støttet av tabeller.
På den andre siden har vi også behov for å hente fram sanger basert på tittel, hvilket antyder en hashtabell, med tittelen som nøkkel og selve sangen som verdi. Ville det vært mulig å bruke en hashtabell? Det er ikke umulig, men heller ikke problemfritt. For det først er en hashtabell uordnet, så vi ville sannsynligvis trenge en tabell i tillegg for å holde styr på listen. Et større problem er at en hashtabell ikke støtter flere nøkler for en og samme verdi. Det ville blitt problematisk for avspillingslisten vår, hvor den samme sangen kan være ført opp for avspilling flere ganger. Derfor holder vi oss til tabeller foreløpig, og søker etter titler ved behov. Dersom dette blir en ytelsesmessig flaskehals, kan vi alltids legge til oppslag via hashtabell senere.
Vi starter vår klasse med den grunnleggende initialize-metoden, som lager det Array-objektet vi vil benytte for som beholder for sangene og lagrer en referanse til dette objektet i instansvariabelen @songs.
class SongList def initialize @songs = Array.new end end |
SongList#append legger den angitte sangen til slutten av @songs tabellen. Den returnerer også self, som er en referanse til det gjeldende SongList objektet. Dette er en nyttig konvensjon som lar oss lenke sammen flere kall til append metoden i en lang kjede. Vi ser et eksempel på dette litt senere.
class SongList def append(aSong) @songs.push(aSong) self end end |
deleteFirst og deleteLast, og implementerer dem på en enkel måte ved å benytte
Array#shift
og
Array#pop
.
class SongList def deleteFirst @songs.shift end def deleteLast @songs.pop end end |
append returnerer SongList-objektet slik at vi kan kjede metodekallene sammen.
list = SongList.new
list.
append(Song.new('title1', 'artist1', 1)).
append(Song.new('title2', 'artist2', 2)).
append(Song.new('title3', 'artist3', 3)).
append(Song.new('title4', 'artist4', 4))
|
nil returneres når listen har blitt helt tom.
list.deleteFirst
|
» |
Song: title1--artist1 (1)
|
list.deleteFirst
|
» |
Song: title2--artist2 (2)
|
list.deleteLast
|
» |
Song: title4--artist4 (4)
|
list.deleteLast
|
» |
Song: title3--artist3 (3)
|
list.deleteLast
|
» |
nil
|
[], som henter fram elementer utifra en indeks. Hvis indeksen er et tall (som vi vil sjekke med
Object#kind_of?
metoden), returnerer vi bare elementet på den posisjonen.
class SongList def [](key) if key.kind_of?(Integer) @songs[key] else # ... end end end |
list[0]
|
» |
Song: title1--artist1 (1)
|
list[2]
|
» |
Song: title3--artist3 (3)
|
list[9]
|
» |
nil
|
[] i SongList som tar en streng og søker etter en sang med den tittelen. Dette virker enkelt nok: vi har en tabell med sanger, så vi går bare igjennom tabellen, et element om gangen, og ser om vi har funnet tittelen vi søker etter.
class SongList def [](key) if key.kind_of?(Integer) return @songs[key] else for i in 0...@songs.length return @songs[i] if key == @songs[i].name end end return nil end end |
for-løkke som itererer over en tabell. Det er da helt naturlig, ikke sant?
Det viser seg at det finnes en måte å gjøre det på som er mer naturlig. Løkken vår er litt for tett innpå tabellen; den spør om en lengde for så å hente ut verdier til den finner det den leter etter. Hvorfor kan vi ikke bare be tabellen kjøre en test mot hvert enkelt element? Jo, vi kan det. Faktisk er det akkurat det som find metoden i Array gjør.
class SongList
def [](key)
if key.kind_of?(Integer)
result = @songs[key]
else
result = @songs.find { |aSong| key == aSong.name }
end
return result
end
end
|
if som en setningsmodifikator for å forkorte koden enda litt.
class SongList
def [](key)
return @songs[key] if key.kind_of?(Integer)
return @songs.find { |aSong| aSong.name == key }
end
end
|
find er en iterator---en metode som gjentar en kodeblokk. Iteratorer og kodeblokker er blant de mest interessante fasilitetene i Ruby, så la oss ta oss tid til å bli kjent med dem (og mens vi gjør det vil vi finne ut akkurat hva den kodelinjen i [] metoden egentlig gjør).
yield setningen.
Hver gang en yield blir utført, kjører den koden i blokken. Når blokken er ferdig, returneres kontrollflyten tilbake til rett etter yield.
[Programmeringsspråk-fantaster vil bli glad for å vite at nøkkelordet yield ble valg for å gjenspeile funksjonen av samme navn i Liskovs språk CLU, et språk som er over tyve år gammelt og fremdeles inneholder egenskaper som ikke har blitt bredt utnyttet av de som ikke har tatt "CLU-et".]
La oss begynne med et enkelt eksempel.
def threeTimes
yield
yield
yield
end
threeTimes { puts "Hello" }
|
Hello Hello Hello |
threeTimes. Inne i denne metoden kalles yield tre ganger etter hverandre. Hver gang kjøres koden som er i blokken, og en hilsen skrives ut. Men det som gjør blokker interessante, er at du kan gi parametre inn til dem, samt motta returverdier fra dem. For eksempel kunne vi skrevet en enkel funksjon som returnerer elementer i Fibonacci-serien opp til en gitt verdi.
[Den grunnleggende Fibonacci-serien er en sekvens av heltall, som starter med to et-tall, hvor hvert enkelt av de resterende elementene er lik summen av de to forrige elementene. Serien blir noen ganger brukt i sorteringsalgoritmer og i analyser av naturlige fenomener.
]
def fibUpTo(max)
i1, i2 = 1, 1 # parallell tilordning
while i1 <= max
yield i1
i1, i2 = i2, i1+i2
end
end
fibUpTo(1000) { |f| print f, " " }
|
1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 |
yield-setningen en parameter. Denne verdien sendes inn til den assosierte blokken. I blokkdefinisjonen er argumentlisten mellom to vertikale streker. I dette eksempelet mottar variabelen f den verdien som ble sendt til yield, slik at blokken skriver ut påfølgende elementer av serien.
(Dette eksempelent viser også parallell tilordning.
Vi kommer tilbake til dette på
side 75)
Selv om det er ganske vanlig å sende bare en verdi til en blokk, er dette ingen begrensning; en blokk kan ha forskjellige antall parametre. Hva skjer hvis en blokk har et annet antall argumenter enn det som gis til yield-setningen? Forbløffende nok viser det seg at samme reglene som vi diskuterte under parallell tilordning viser seg igjen (med en liten forskjell: flere argumenter til en yield konverteres til en tabell dersom blokken kun tar ett argument).
Argumentvariablene til en blokk kan være de samme som eksisterende lokale variable. Hvis så, vil den nye verdien til variabelen være tilgjengelig etter at blokken er ferdig. Dette kan føre til overraskende oppførsel, men samtidig er det muligheter for å øke ytelsen med å bruke variabler som allerede eksisterer.
[For mer informasjon om dette og andre potensielle feller, se liste som begynner på
side 129;
mer informasjon om ytelse begynner på
side 130
]
En blokk kan som sagt også returnere en verdi tilbake til metoden. Verdien til det siste uttrykket som blir evaluert i blokken, sendes tilbake til metoden som resultat fra kallet til yield. Dette benytter find metoden i Array seg av.
[Implementasjonen av find metoden er egentlig definert i modulen Enumerable, som har blitt mikset inn i Array klassen.]
Implementasjonen kunne sett omtrent slik ut:
class Array
|
||
def find
|
||
for i in 0...size
|
||
value = self[i]
|
||
return value if yield(value)
|
||
end
|
||
return nil
|
||
end
|
||
end
|
||
|
||
[1, 3, 5, 7, 9].find {|v| v*v > 30 }
|
» |
7
|
true, returnerer metoden det elementet den er kommet til. Hvis ingen elementer fører til at blokken returnerer true, returnerer metoden nil.
Eksempelet viser fordelen med denne måten å gjøre iterering. Array klassen gjør det den er best til, som er å romstere i og hente frem elementer fra tabeller, og overlater til applikasjonskoden å fokusere på sin oppgave (som her er å finne et element som oppfyller et matematisk kriterium).
Noen iteratorer er felles for flere typer samlinger i Ruby. Vi har allerede sett find iteratoren. To andre er each og
collect. Iteratoren each er sannsynligvis den enkleste---den gjør ikke noe mer enn å gi alle elementene sine til blokken i tur og orden.
[ 1, 3, 5 ].each { |i| puts i }
|
1 3 5 |
each har en spesiell betydning i Ruby;
på side 87
vil vi beskrive hvordan den er basisen for språkets for-løkke og
på side 104
viser vi hvordan det å definere en each metode kan gi deg mye ekstra funksjonalitet gratis.
En annen iterator som ofte blir brukt, er collect. Den tar hvert element fra samlingen og sender det til blokken, for deretter å fylle opp en ny tabell med resultatene fra blokken.
["H", "A", "L"].collect { |x| x.succ }
|
» |
["I", "B", "M"]
|
yield hver gang den genererer en ny verdi. Det som bruker iteratoren er bare en kodeblokk assosiert med metodekallet. Man trenger ikke å skrive hjelpeklasser for å holde på iteratorens tilstand, slik som man må i Java og C++. Dette, som mange andre ting, gjør Ruby til et veldig transparent språk.
Når du skriver et program i Ruby, kan du konsentrere deg om jobben du vil ha gjort, og mindre på å bygge opp stillaskode for å støtte selve språket i sitt arbeid.
Iteratorer trenger ikke begrense seg til å hente ut eksisterende data i tabeller og hashtabeller. Som vi så i eksempelet med Fibonacci-serien, kan en iterator returnere verdier den utleder eller regner seg fram til. Dette benytter Ruby sine innput/utput klasser seg av, som har iterator-grensesnitt som returnerer påfølgende linjer (eller tegn) i en innput/utput-strøm.
f = File.open("testfile")
f.each do |line|
print line
end
f.close
|
This is line one This is line two This is line three And so on... |
inject metoden.
sumOfValues "Smalltalk metode" ^self values inject: 0 into: [ :sum :element | sum + element value] |
inject fungerer som følger. Den første gangen den
tilknyttede blokken blir kalt, blir sum satt til verdien som
inject metoden mottok som parameter (null i dette tilfellet),
og element er satt til det første elementet i tabellen. Andre og
påfølgende kall til blokken, blir sum satt til den verdien som
blokken returnerte på forrige kall. På denne måten kan man kumulativt regne
ut totalen i sum. Den siste verdien fra inject
metoden er verdien blokken returnerte siste gangen den ble kalt.
Ruby har ingen innebygd inject metode, men det er ikke vanskelig å lage vår egen. I dette tilfellet legger vi den til klassen Array, men senere på
side 102(??) vil vi vise hvordan man kan gjøre metoden generelt tilgjengelig.
class Array
|
||
def inject(n)
|
||
each { |value| n = yield(n, value) }
|
||
n
|
||
end
|
||
def sum
|
||
inject(0) { |n, value| n + value }
|
||
end
|
||
def product
|
||
inject(1) { |n, value| n * value }
|
||
end
|
||
end
|
||
[ 1, 2, 3, 4, 5 ].sum
|
» |
15
|
[ 1, 2, 3, 4, 5 ].product
|
» |
120
|
class File
def File.openAndProcess(*args)
f = File.open(*args)
yield f
f.close()
end
end
File.openAndProcess("testfile", "r") do |aFile|
print while aFile.gets
end
|
This is line one This is line two This is line three And so on... |
openAndProcess er en klassemetode---den
kan kalles uavhengig av et faktisk File-objekt.
Vi ønsker at den skal ta de samme argumentene som den vanlige
File.open
metoden, men vi bekymrer oss egentlig ikke i det hele tatt om hva disse argumentene er. Istedet spesifiserer vi argumentene som *args, som betyr ``samle de faktiske parametrene som ble sendt til metoden inn i en tabell.''
Vi kaller dernest File.open og sender med *args som parameter. Dette ekspanderer tabellen tilbake til individuelle parametre. Nettoresultatet er at openAndProcess blir gjennomsiktig i at hva enn parametre den mottar, så blir de sendt videre til
File.open
.
Når filen så har blitt åpnet, kaller openAndProcess blokken ved å bruke yield, med det åpne filobjektet som parameter til blokken. Når blokken så avsluttes, lukkes filen. På denne måten har ansvarligheten for å lukke en åpnet fil blitt flyttet i fra brukeren til filobjektene selv.
Sist, men ikke minst, bruker dette eksempelet do...end for å definere en blokk. Den eneste forskjellen mellom denne notasjonsformen og bruk av klammeparenteser, er presedens:
do...end binder lavere enn
``{...}''. Vi forklarer hvilke effekter dette har på
side 236.
Denne teknikken hvor filene holder styr på seg selv,
er så nyttig at klassen File-klassen i Ruby støtter den direkte.
Hvis et kall til
File.open
har en blokk tilknyttet, da vil den blokken bli kalt med filobjektet som argument, og filen vil bli lukket når blokken er ferdig.
Dette er interessant, da det betyr at
File.open
kan oppføre seg på to forskjellige måter: når den blir kalt med en blokk, utfører den blokken og lukker filen. Når den kalles uten en blokk, returnerer den bare filobjektet. Dette gjøres mulig av metoden
Kernel::block_given?
, som svarer true hvis en blokk er tilknyttet det metodekallet vi er i.
Med å bruke den, kunne du implementert
File.open
(nok en gang uten feilhåndtering) slik som følgende.
class File def File.myOpen(*args) aFile = File.new(*args) # Hvis der er en blokk, send inn filen til den og # lukk filen når blokken returnerer if block_given? yield aFile aFile.close aFile = nil end return aFile end end |
bStart = Button.new("Start")
bPause = Button.new("Pause")
# ...
|
Button-klassen har maskinvarefolka gjort det slik at en tilbakekallsmetode, buttonPressed, vil bli kalt.
Den åpenbare måten å legge til funksjonalitet til disse knappene er å lage subklasser av Button, hvor hver av subklassene implementerer det vi vil skal skje i buttonPressed-metoden.
class StartButton < Button
def initialize
super("Start") # kall initialize-metoden til Button
end
def buttonPressed
# gjør det som må til for å starte avspilling...
end
end
bStart = StartButton.new
|
Button endrer seg, kan det føre til mye vedlikeholdsarbeid.
For det andre, så er handlingene som skjer når en knapp trykkes, uttrykket på feil nivå; de er ikke en del av knappen, men en egenskap av den automatiske platespilleren som bruker disse knappene. Vi kan løse begge disse problemene med å bruke blokker.
class JukeboxButton < Button
def initialize(label, &action)
super(label)
@action = action
end
def buttonPressed
@action.call(self)
end
end
bStart = JukeboxButton.new("Start") { songList.start }
bPause = JukeboxButton.new("Pause") { songList.pause }
|
JukeboxButton#initialize.
Hvis den siste parameteren i en metodedefinisjon er prefikset med et og-tegn (for eksempel &action), tar Ruby og ser etter en kodeblokk når metoden kalles.
Den blokken blir konvertert til et Proc-objekt og tilknyttet parameteren. Du kan da håndtere parameteren som enhver variabel. I vårt eksempel, legger vi den i instansvariabelen @action. Når tilbakekallsmetoden buttonPressed kalles, bruker vi
Proc#call
for å kjøre koden i blokken.
Så hva har vi egentlig når vi har et Proc-objekt?
Interessant nok er det mer en bare en kodebit. Til en blokk (og dermed også et Proc-objekt) er all omliggende kontekst som blokken ble definert i: verdien til self og metodene, variablene og konstantene i skopet.
En del av Ruby sin magi er at blokken kan bruke alt av denne skopinformasjonen selv om miljøet blokken ble definert i, hadde forduftet. I andre språk, kalles denne egenskapen for tillukking (eller closure).
La oss se på et oppkonstruert eksempel. Her brukes metoden proc til å konvertere en blokk til et Proc-objekt.
def nTimes(aThing)
|
||
return proc { |n| aThing * n }
|
||
end
|
||
|
||
p1 = nTimes(23)
|
||
p1.call(3)
|
» |
69
|
p1.call(4)
|
» |
92
|
p2 = nTimes("Hello ")
|
||
p2.call(3)
|
» |
"Hello Hello Hello "
|
nTimes returnerer et Proc-objekt som tar tak i metodens parameter aThing. Selv om denne parameteren er utenfor skopen innen blokken kalles, forblir parameteren tilgjengelig for blokken.
( In progress translation to Norwegian by NorwayRUG. $Revision: 1.25 $ )
| Forrige < |
Innhold ^
|
Neste >
|